INANet Dateset for Splicing
 NANet
NANetDataset Introduction
The NANet Dataset is a synthetic dataset specifically designed for splicing forgery detection, using the MSCOCO datasets as its foundational sources. There are 113,964 forgery images in NANet. In this dataset, the positively labeled instances correspond to tampered regions, whereas the negatively labeled instances pertain to non-tampered regions. A pair of positive and negative region belongs to the same category to ensures a reasonable semantic relevance of tampered images within the NANet dataset.
Generating Process
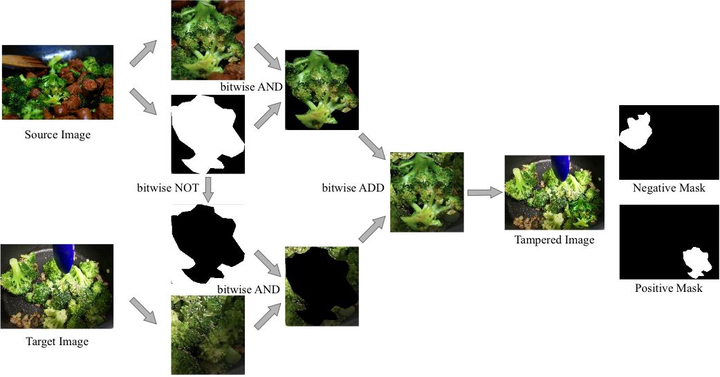
To illustrate the methodology employed by NANet in constructing the synthetic tampering dataset, Fig. 3 outlines the process of generating a splicing image. The pre-training network of NANet necessitates a pair of positive and negative instances to effectively discern dissimilarities between tampered and non-tampered regions, it is necessary to have masks for both the tampered and non-tampered regions on a single forgery image to serve as supervision during the training process. We obtain the masks of the objects on the images directly from the MSCOCO dataset and synthesize a stitched-tampered image by various image operations in Fig. 3. The process ensures the semantic information consistency between the randomly selected tampered objects and the target image by comparing their respective categories and sizes. To ensure the semantics of the tampered images and to improve the robustness of NANet, we add some random manipulation attacks in the process of generating the synthetic tampering dataset.
Advantages
To enable the model to distinguish between tampered and non-tampered objects in tampered images, a tampered image in the synthetic tampered dataset is paired with markings for both tampered and non-tampered objects. This concept is distinct from previous traditional or synthetic tampering datasets and more suitable for models with triplet loss functions used in tampering detection.