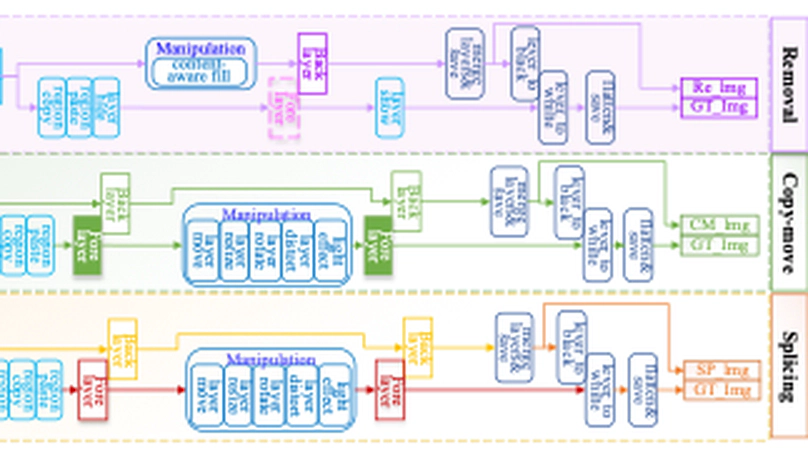
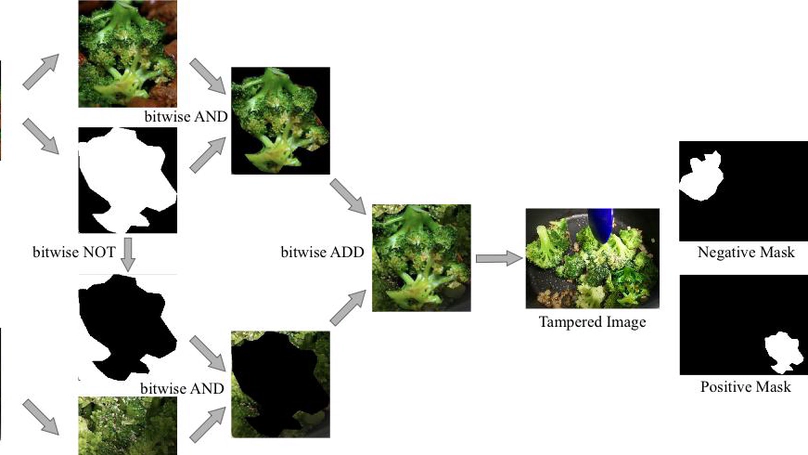
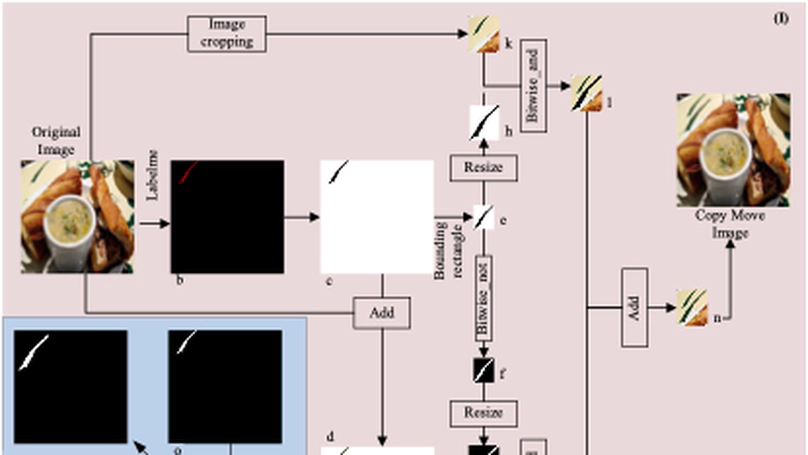
IML-MPU is a large-scale synthetic forgery dataset generating by Photoshop scripting (PS-Scripting), using a diverse set of samples sourced from VISION, KCMI, and own photographs selected as original images. The dataset comprises three distinct subsets, namely copy-move, splicing, and removal, consisting of 38,000, 43,000, and 32,000 images, respectively. It contains uncompressed TIFF images and JPEG images with different compression factors.