IML-MPU Dataset for Multi-Tamper (Splicing, Copy-Move and Removal)
 IML-MPU
IML-MPUDataset Introduction
IML-MPU is a large-scale synthetic forgery dataset generating by **Photoshop scripting (PS-Scripting)**, using a diverse set of samples sourced from VISION, KCMI, and own photographs selected as original images. The dataset comprises three distinct subsets, namely copy-move, splicing, and removal, consisting of **38,000**, **43,000**, and **32,000** images, respectively. It contains uncompressed TIFF images and JPEG images with different compression factors.
Generating Process
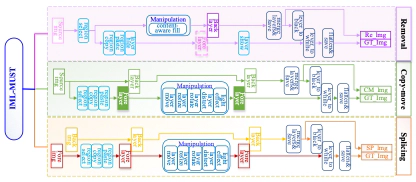
We employ Labelme to select foreground areas from the original image that include various shapes such as objects, circles, rectangles, triangles, and arbitrary shapes. Fig. 4 illustrates the step-by-step procedure involved in generating multi-tamper images. For generating splicing images, we randomly choose two images, one as the background image and the other as the donor image. In the case of copy-move and removal manipulations, a single image is selected. To simulate human-like operations, the dataset applies common image transformations such as distortion, rotation, and scaling to the selected regions obtained through Labelme. To make the tampered region more difficult to detect, common editing techniques like blurring, and illumination are used to eliminate visually distinguishable traces. The forgery image is saved as a TIFF file directly without compression, or randomly selected the JPEG compression quality commonly used in Photoshop to save as a JPEG file.
Advantages
Compared to previous works, our strategy has two distinct advantages. First, the IML-MPU dataset exhibits significant flexibility and customization in the synthesis procedure. Compared to the rectangle PS-boundary dataset, it better simulates real-world image manipulated scenarios. Second, in addition to copy-move and splicing, the IML-MPU dataset also includes removal manipulation, which the PS-boundary dataset does not have.