AI model parameter protection
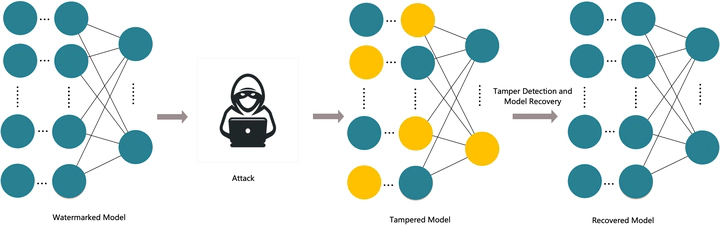 Photo by rawpixel on Unsplash
Photo by rawpixel on UnsplashIn the current absence of effective protection measures for artificial intelligence model parameters, malicious actors are increasingly focusing on deep learning models, attempting to compromise data integrity through illegal means. Tampering with model parameters has become a common method of attack, introducing potential vulnerabilities by modifying these parameters and thereby disrupting the model. Currently, mainstream model watermarking methods are mostly applied to copyright protection issues, with little mention of research on protecting model parameters. In response to common model tampering attacks, we are researching a white-box model parameter protection strategy based on fragile watermarking, aiming to maintain model performance by safeguarding model parameters. In the embedding phase of the white-box watermark, to ensure minimal impact on model performance and sufficient sensitivity to data tampering, we employ watermarking technology to protect model performance. This technique aims to minimize the negative impact on model performance while maintaining high sensitivity to data tampering during watermark embedding. It is well-known that parameter tampering can lead to a sharp decline in model performance. Our research focuses on achieving the ability to locate and self-recover from parameter tampering.