SPANet Dataset for Copy-Move
 SPANet
SPANetDataset Introduction
The SPANet Dataset is a synthetic dataset specifically designed for copy-move forgery detection, using the SUN and MSCOCO datasets as its foundational sources. The dataset consists of 550 basic forgery images, including a diverse range of **12 attack types** within rotation and scaling variations, and **11 post-processing techniques**. Therefore, the number of forgery images in SPANet Dataset is 550 * 12 * 11 = **72600**.
Generating Process
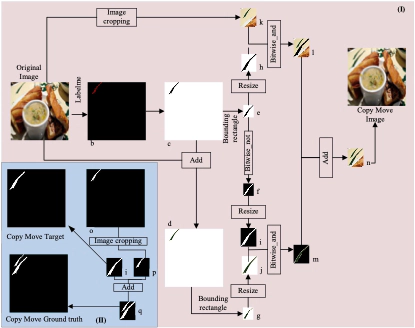
The specific generation flows are shown in Fig. 1 and Fig. 2. First, we manually select the tamper target through Labelme based on the Original Image and generate the corresponding mask. After obtaining the minimum rectangles e and f of the tamper target and resizing them using binary operations, the final copy-move forgery image is generated using the Region of Interest (ROI) selection algorithm in OpenCV. The representation of this workflow is illustrated in Figure 1 (I), while Figure 1 (II) presents the similarity flow for corresponding ground-truth generation.
Advantages
1.3SPANet Dataset processes local tamper regions and global forgery images more comprehensively than the existing public copy-move forgery dataset and involves various post-processing for the robustness of training network. Due to the random forgeries in digital images, we select many areas that are meaningless or does not contain specific objects as sources of tampering to enrich the dataset. In addition, the intermediate output of the SPANet dataset generation process can serve for our future research on distinguishing source and target for copy-move images forgery.